Machine Learning Enables Stable Long-Term Control in Microfluidic Experiments
- Ankit Jain

- Sep 3, 2018
- 2 min read
Reinforcement learning has been successfully used for stable long-term droplet generation and laminar flow control experiments
Dr. Oliver Dressler from our group has developed a novel machine learning-based control methodology for stable long-term experiments in microfluidics. In his experiments, he has successfully shown human-like and in some cases, super-human-like performances using reinforcement learning-based algorithms.
Microfluidic devices often show inconsistent performance when operated over extended timescales. Such variations in performance are due to a multiplicity of factors, including microchannel fouling, substrate deformation, temperature and pressure fluctuations, and inherent manufacturing irregularities. As a result, human intervention is needed to adjust the input parameters, such as flow rates and temperature, during a long-term microfluidic experiments. On the other hand, machine-learning algorithms can provide an automated control strategy, obviating such human mediation. Consequently, Oliver used reinforcement learning—a machine learning technique—for solving two basic experimental problems in microfluidics, namely stable size control in droplets and interface control between miscible liquids.
In reinforcement learning, the algorithm repeatedly interacts with an environment such as the microfluidic channel and iteratively maximizes a rewardsignal obtained from the environment. Herein, the algorithm controlled the flow rates of two fluids in the microfluidic chip and a subsequent reward signal was fed-back to the algorithm based on image processing of camera observations. Oliver assigned the highest reward to the flow rates that generated a defined droplet size or specific laminar flow liquid interface position. During the training phase, the system was allowed to change flow rates randomly within specified constraints to learn to maximize the reward. After a certain time, the system showed equal or superior performance in controlling the size of the droplets and laminar flow interface when compared to a human agent. The system also showed the ability for self-recovery from unexpected bubble formations—a common problem in microfluidics—in both experiments.
This novel reinforcement learning-based control strategy can provide new opportunities for automated long-term experiments in microfluidics, benefitting on-going chemical and biological studies.
Written by Ankit Jain.
Read the full paper here.
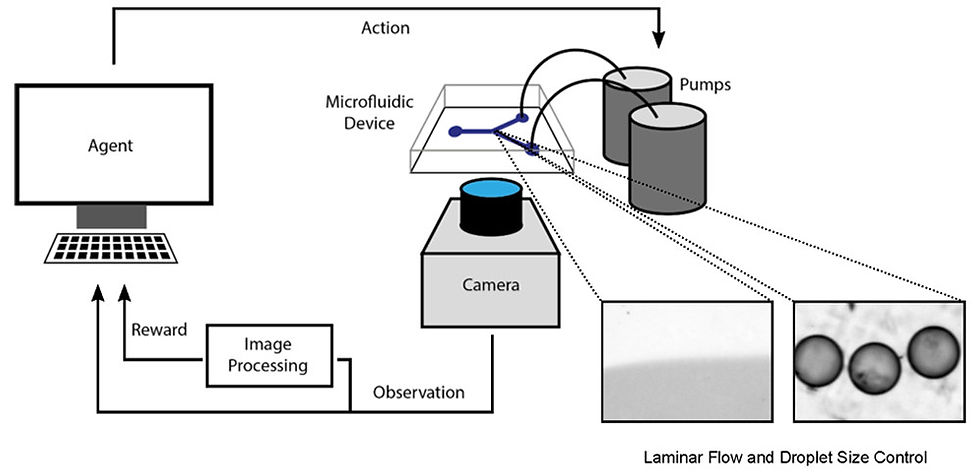
Reinforcement learning used for laminar flow and droplet size control experiments.
Comments